

- 「BERT」とは
- 自然言語処理とは
- 「BERT」導入の背景と仕組み
- 「BERT」でできること、特徴
- 「BERT」を活用した事例:コンプライアンス領域の業務生産性向上
(1)業務課題:ネガティブニュースの抽出・分析の堅確化・効率化
(2)「BERT」を活用したニュースラベリングAIシステムの開発
(3)実務適用での課題・ハードル - 今後の展開余地について
「BERT」とは

BERTは、Bidirectional Encoder Representations from Transformersの略で、Googleが2018年に発表した自然言語処理(NLP)分野で革命をもたらした深層学習モデルの一つです。BERTの革命的な点は、文章中の単語をその前後の文脈とともに理解する能力にあります。従来の自然言語処理(Natural Language Processing, NLP)モデルは、テキストを一方向からしか見ることができず、単に単語の単独の意味しか捉えられませんでしたが、BERTは双方向性を持っているため、文の構造を考慮し、文脈上のニュアンスをより正確にとらえることができます。
自然言語処理とは

自然言語処理は、人間が使用する言語(自然言語)をコンピューターが理解し、分析、処理するための技術分野です。これには、文章の分類、構文解析、単語の意味解析、文章生成、音声認識などが含まれます。NLPは、人間とコンピューターのコミュニケーションを改善するために重要であり、ビッグデータ分析や意思決定をサポートするために非常に重要な分野となっています。自然言語処理の具体的な応用例としては、音声認識とアシスタントを行うSiriやAlexa、Google翻訳などの機械翻訳、カスタマーサービスでよく使用されるチャットボットなどがあり、多くのアプリケーションに利用されています。しかし、自然言語処理には多くの課題があります。特に自然言語の持つ「曖昧さ」は大きな問題です。例えば、「回答」「解答」「解凍」のように、同じ発音でも文脈によって異なる意味を持つ言葉が多く存在します。このような曖昧さを解消するには、文脈を理解する高度なアルゴリズムが必要となります。
(出典: Freepik 1)
「BERT」導入の背景と仕組み

これまでのNLPモデルの多くは、単語の周囲の文脈を十分に考慮せず、一方向にテキストを解析していました。これは同音異義語、多義語、文脈に依存する意味など、自然言語の曖昧さや複雑さを適切に処理するのに限界がありました。BERTはこの問題を解決するために開発されました。
BERTは「Transformer」というニューラルネットワークのアーキテクチャを採用しています。これは並列処理に優れ、単語の前後の情報を同時に考慮することができます。両方向からの情報を同時に活用することで、文脈に基づくより豊かな単語の表現を学習します。これにより、同じ単語が異なる文脈で異なる意味を持つ場合、それをうまく処理し、文の意味をより正確に把握することができるようになりました。
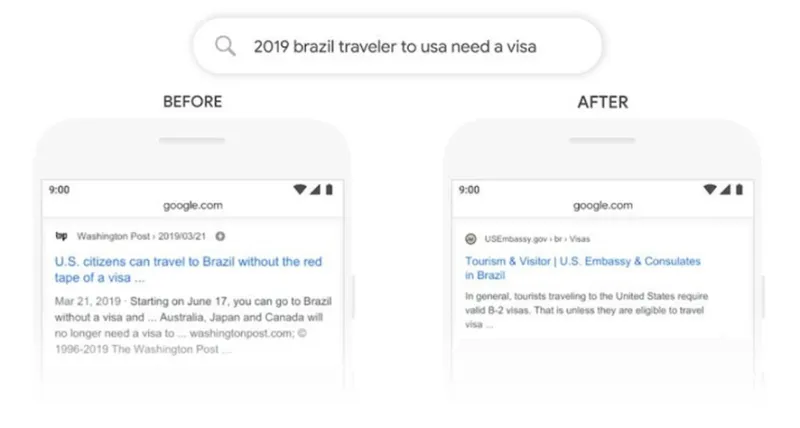
Googleから発表されたBERTの具体的な成果事例として、「2019 brazil traveler to usa need a visa」という検索クエリが挙げられています。これは「2019年にブラジルからアメリカへ旅行する場合、ビザが必要か?」という情報が求められています。このクエリでは、「to」とその前後の単語との関係は特に重要で、「ブラジルからアメリカへ」を示していますが、以前のアルゴリズムでは、この「to」との関係性を正確にとらえることができず、結果として「アメリカからブラジルへ」に関する情報が上位に表示されてしまっていました。
しかし、BERTの導入により、検索エンジンは「to」の意味を適切に理解し、「ブラジルからアメリカへの入国」に関する、ユーザーのニーズに合った検索結果を表示することが可能になりました。
(出典) Google 2
BERTは自然言語の曖昧さや複雑さといった課題に対処するための強力なモデルであり、自然言語処理の分野で革命的な影響を及ぼしました。
「BERT」でできること、特徴

自然言語処理(NLP)分野は日進月歩で進化しており、BERTはその中で画期的な存在となっています。では、BERTができることとその特徴は何なのでしょうか。
① コンテキストの理解
まず、BERTは従来のNLPモデルとは異なる構造を持っています。従来のNLPモデルはCNNやRNNといったニューラルネットワークを使用していましたが、BERTは「Transformer」というニューラルネットワークのアーキテクチャを採用しています。このTransformerを活用することで、文の前後関係を同時に考慮しながらテキストを解析することが可能となり、それまでのモデルにはなかった高い性能を発揮します。
② 転移学習
また、BERTの重要な特徴として転移学習があります。転移学習とは、あるタスクで学習したモデルの知識を、別のタスクに適用するプロセスです。これは、BERTをベースにしたモデルを、特定のタスクに特化させるために既存のモデルに追加して再学習することです。転移学習のおかげで、少量のデータでも高い精度を持ったモデルを短時間で構築することができます。これは、多くのデータを用意するのが難しい場合や時間が限られている場合に非常に有益です。
③ 学習データ不足の解消
さらに、従来のNLPモデルでの大きな課題だった「学習用データの不足」も、BERTではうまく解消されています。これまでのNLPモデルの学習データは、ラベル付与などに時間とコストがかかっていました。しかし、BERTではインターネット上に存在するラベルの付いていない大量のテキストデータを利用して、モデルを事前学習します。これにより、コストを抑えつつ、豊富なデータを活用して高い性能を実現しています。
これらの特徴により、BERTは自然言語処理の分野で革新的な影響を及ぼし、多くの応用例が生まれています。テキスト解析、文章生成、機械翻訳、音声認識といった多岐にわたる分野でBERTは活躍しており、これからもその可能性は広がり続けるでしょう。
BERTの登場によって、NLPの研究も加速しています。多くの研究者が、BERTをベースにしてさらに高度なモデルを開発しようとしており、その応用範囲はさらに広がりを見せています。
「BERT」を活用した事例:コンプライアンス領域の業務生産性向上 3

(1)業務課題:ネガティブニュースの抽出・分析の堅確化・効率化
三菱UFJ信託銀行では、国内外での有価証券投資を対象とした市場運用業務において、投資判断のために様々な情報の収集・分析を実施しています。しかし、複数の情報源から配信される大量のビジネス関連情報の中から、投資判断に影響を与えうる重要なネガティブニュースを短時間で抽出・分析・精査するには、相応の知識と時間を要するため、業務の生産性の面で課題があると認識していました。
(2)「BERT」を活用したニュースラベリングAIシステムの開発
その課題に対応するため、三菱UFJ信託銀行は、MILIZE社と共同で、ネガティブニュースのラベリングAIシステム「NEWS AI SEARCHER」を開発しました45。本システムは、ニュースベンダーの記事を含む複数の情報ソースから配信される様々なビジネス関連情報に対して、上述の「BERT」を用いて特定の情報を抽出し、ラベリング・分類を行うものです。本システムの開発により、業務運営の堅確化と、作業時間の短縮による効率化を実現しました。
NEWS AI SEARCHERは、アンチ・マネーロンダリング(AML:Anti-Money Laundering)や経済制裁、規制違反などのブラックワードをキーとして、日々配信される様々な情報源(ニュースベンダーの情報データベースなど)からネガティブニュースを抽出します。そして、機械学習モデルが、独自の文脈を持つものにラベル付けし、優先順位付けを行います。具体的には、AML・経済制裁などに関連するニュース記事や、AML・経済制裁などにつながる可能性がある投資・経済活動に関連するニュース記事、ネガティブワードを含むその他のニュース記事をラベリングします。
これにより、優先度の低いニュース記事を短時間で見極め、投資判断に影響を及ぼす可能性のある重要度の高いネガティブニュースを迅速に特定・精査することが可能となりました。また、重要なネガティブニュースを見逃すリスクを回避することで、業務をより堅確化するだけでなく、ニュース記事のラベリングと優先順位付けにより、ネガティブニュース分析業務の大幅な削減(年間約11,000時間の作業時間削減)という効率化も実現しました。迅速な投資意思決定が命である市場運用業務において、投資判断の際のデューデリジェンス・プロセスの円滑化にもつながっています。
(3)実務適用での課題・ハードル
金融機関の業務においては、AIの実務への適用はまだ先進的な取り組みであるという意識が強く、業務への適用には慎重な意見が多く挙がりました。特にNEWS AI SEARCHERは、コンプライアンス領域の中で、近年国内外で監視の目が厳しくなり、厳格な管理が求められているAMLや経済制裁の領域への適用を目指していたため、その傾向が顕著でした。指摘された意見のひとつは、「重大なネガティブニュースを見逃すリスク」が存在するのではないかというものでした。この回避策として、当初はAIを活用して重大なネガティブニュースだけを絞り込む運営フローを検討していましたが、最終的には人の目によってニュース記事全件を確認するという運営に見直しを図っています。仮に全てのニュース記事を閲覧したとしても、ラベリングによってニュース記事の検証に軽重を付けることで、確認に要する総時間を大幅に短縮することができ、業務効率の向上に大きく寄与しました。
その他、「AIがラベリングを間違えるリスク」や「その間違いが継続してしまうリスク」が存在するのではないかという意見も挙がりました。それらについては、当然ながらAIは万能ではなく、間違いが起きるリスクは内在しているが、間違いを修正する機能を具備していることを説明し、理解を得ました。具体的には、ラベリングの修正が必要なニュース記事については、担当者が当該ニュースを特定した上でAIに再学習させる仕組みを実装しており、AIの陳腐化を防ぐとともに、ラベリング精度の維持・向上を実現しています。
今後の展開余地について

今後の展開余地については、まずは、三菱UFJ信託銀行の市場部門内においてNEWS AI SEARCHERを活用したネガティブニュース活用のリスク評価の態勢の定着を図るとともに、社内の他部門や海外支店の利用ニーズを調査し、希望部署へのサービス展開と提供を検討しています。そのうえで、グループ内の他業態への拡大も視野にいれています。最終的には地域金融機関を含む他行や事業会社へのサービス提供も検討したいと考えています。
機能拡充の観点では、現在は英語ニュースを対象に法人(企業名)を検索する機能のみを搭載していますが、他行等ヒアリングの結果、日本語ニュースに対して個人名を検索するニーズが高いことを確認したため、新たに日本語ニュースのソースを追加し、固有名詞(個人名)を含有するネガティブニュースを、優先順位を付けて抽出するようなAI機能の開発も検討しています。
利用用途拡大の観点では、NEWS AI SEARCHERのフレームワークを活用し、AML・経済制裁や規制違反のネガティブニュースのみならず、例えば、信用リスクに影響を与えるようなネガティブニュースを抽出するような使い方の提案により、利用用途の拡大も想定しています。更には、ネガティブニュースとは真逆のポジティブニュースを対象に抽出するような機能を具備させることで、例えばSDGsの観点で、投資に値するような優良な企業を抽出し、投資という形で当該企業を支援することで、社会課題の解決に繋げ、間接的に世の中に貢献することも可能であると考えています。
リスク評価にネガティブニュースを活用し、さらにはネガティブニュースの抽出にAIを活用したシステムを利用することは現段階では先進的な取り組みであると考えます。しかしながら、リスク評価におけるネガティブニュースの活用は、早晩主流になる手法であると考えています。我々は金融機関として、まずはコンプライアンス領域において、自らが率先して堅確、且つ効率的な態勢を維持することが大命題であるとともに、同時にビジネスの発展にも寄与すべく市場運用業務を拡大させていくことを使命と考えています。本システムの展開が、社会的意義があるものとして、盤石なコンプライアンス基盤の提供と、市場運用業務の円滑な運営に寄与し、安心のうえでのビジネス発展に貢献出来ればと考えています。
<参考文献>
- Freepik ↩︎
- “Understanding searches better than ever before,” Google, 2019. ↩︎
- 「金融AI成功パターン」、(著)金融データ活用推進協会、日経BP、pp.301-317(第13章)、2023/2/27. ↩︎
- 「AI活用によるネガティブニュース記事ラベリングシステムの共同開発について」、三菱UFJ信託銀行ニュースリリース、2022/7/4. ↩︎
- 「AIとFintechのMILIZEは、AI活用によるネガティブニュース記事ラベリングシステムを三菱UFJ信託銀行と共同開発」、MILIZEニュースリリース、2022/7/4. ↩︎

- 寄稿
- <1章~4章>
株式会社MILIZE 金融AI・DX企画部
中村 由梨花 氏
- 寄稿
- <1章~4章>
株式会社MILIZE AIコンサルティング部 副部長
熊谷 壮一郎 氏
- 寄稿
- <5章~6章>
三菱UFJ信託銀行株式会社 市場企画部 次長
橋本 育子 氏
- 寄稿
- <5章~6章>
三菱UFJ信託銀行株式会社 市場デジタル推進部 上級調査役
木村 俊洋 氏
- 寄稿
- <5章~6章>
三菱UFJ信託銀行株式会社 市場デジタル推進部 兼 デジタル企画部 上級調査役
菊地 剛正 氏







