

※この講座は所属企業や所属団体とは一切関係ありません
運用の仕方例(PrecisionとRecall)

予測モデルができても、それだけでは何も運用できない。では、その予測値を使ってどのようにビジネスに役立てるのかについて簡単な例を用いて説明する。
例えばあるサービスの不正利用者を予測し、不正利用している確率を出力する予測モデルが出来たとする。このとき, 一人も不正利用者を逃したくなければ予測モデルの出力値に関係なく、全件を人間が目で見てチェックすれば良いが、それでは人件費がかかりコストが大きい(人間が目検をすると不正していることは分かるものとする)。不正利用者は利用者全体の0.1%しかいないと仮定する(例えば正しい利用者99,900人、不正利用者100人)と、人間による目検のほとんどが正しく利用している人の確認となって無駄が多い。
そこで予測モデルの出力値を高い順に並べて、ある数値(=目検閾値)よりも高いものは予測モデルが不正利用者と予測したとみなして目検をし、低いものは不正利用をしていないとして、目検をしないとする(つまり、不正利用者が含まれていたら見逃される)。
このとき、目検する対象の不正利用率(=目検される不正利用者数/目検される数)をPrecisionといい、全体の不正利用者の内で目検対象に含まれている不正利用者の割合(=目検される不正利用者数/全体の不正利用者数)をRecallという。このPrecisionとRecallはトレードオフの関係にあり、一方を高めようとするともう一方が低くなってしまう。下記は、ある不正利用データに対して不正利用者を予測するモデルの出力値に対して、目検閾値を変化させたときのPrecisionとRecallの関係である。
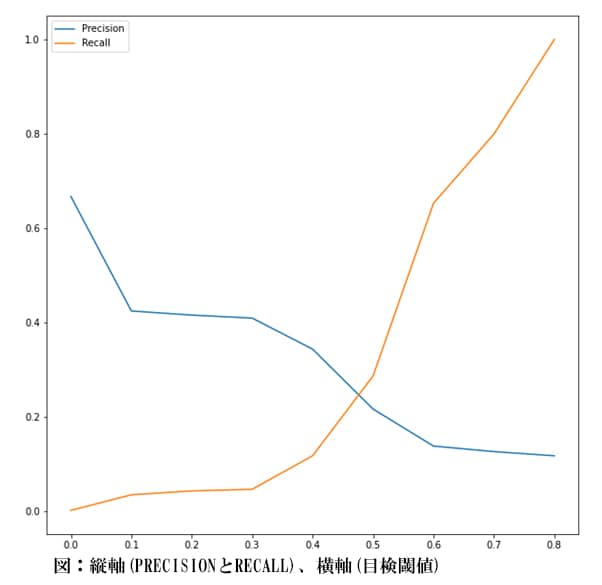
上記の図を見て分かるように、Precisionを高くするような目検閾値を選ぶとRecallが低くなってしまい不正利用者を多く見逃してしまう。
逆にRecallを高くするような目検閾値を選ぶとPrecisionが低くなってしまう。このとき、目検閾値が高いと目検数はもちろん少なく、目検閾値が低いと目検数は多くなる。
したがって、目検閾値をどのような値に設定するのかは、不正利用者をどれくらい見逃してよい問題なのか?コスト削減の重要度はどれくらいなのか?を天秤にかけて、そのプロジェクトについての背景を考慮した上で、丁度良い目検閾値を設定する必要がある。このように、目検閾値をプロジェクトの意思決定者とすり合わせてから、実際に運用するケースがある。
▼データサイエンスを基礎から応用まで学ぶ
【オンライン受講】【データサイエンス実務基礎】Pythonで体感!はじめての機械学習
【会場受講】【データサイエンス実務基礎】Pythonで体感!はじめての機械学習
【オンライン受講】【データサイエンス実務応用】Pythonで実践!ディープラーニング
【会場受講】【データサイエンス実務応用】Pythonで実践!ディープラーニング
ビジネス上のリーク
リークとは、本来想定されていない方法で、目的変数あるいはそれに近いものが説明変数に漏れていて、機械学習モデルが学習できてしまうことである。リークの例は沢山あるが、いくつか挙げると以下の点などがある。
- 未来の情報が入っている
- 無意味と思ったIDに意味がある
- 検証データとしてHold Outしたつもりが正しく分割できていない(実質同じデータが構築と検証に混在している)
リークは説明変数の選択や、モデル構築データとモデル検証データの設計時に発生し、自動でリークを検出するのは現状では難しい。
検証の枠組みを「人間」がしっかり考える

上記のリークで説明した通り、構築した予測モデルをどのようなデータで検証するのかについては統計や機械学習では解決ができません。なぜならば、元となるデータの生成過程やデータ周りの知識が重要となるからです。したがって「人間」がしっかりと考えて検証を行わなければいけなく、2,3年後に自動化されるようなものでもありません。
データ分析で大切なこと

全4回で一貫して伝えたかったこととしては、機械学習やデータ分析は泥臭いものであり、決してバズワードとしてのデータサイエンティストのように、華やかさだけの職業ではなく、泥臭い職人のような職業であるということです。
全4回を通して機械学習に興味を持って頂き、機械学習を勉強していただけたら、この記事の目的としては幸いです。最後にデータ分析で大事なことはデータを穴が開くほど眺めること、まずは手を動かすことなどです。ぜひ第一歩を踏み出して頂けたらと思います。
▼データサイエンスを基礎から応用まで学ぶ
【オンライン受講】【データサイエンス実務基礎】Pythonで体感!はじめての機械学習
【会場受講】【データサイエンス実務基礎】Pythonで体感!はじめての機械学習
【オンライン受講】【データサイエンス実務応用】Pythonで実践!ディープラーニング
【会場受講】【データサイエンス実務応用】Pythonで実践!ディープラーニング

- 寄稿
-
Kaggle Master
佐野 遼太郎 氏Kaggle Masterの称号を持つ。2015年4月よりコンサルタント
として金融機関を中心としたデータ分析・モデル構築業務に従事。
2018年2月にKaggler枠でディー・エヌ・エーに入社、現在は
Mobility Technologiesに出向中。また、2016年から
社外データ分析講座講師として300人を超えるデータ分析技術者の
人材育成に関わっている
※経歴などは2021年3月末時点のものです










