

- はじめに
- カテゴリ変数を扱う上での注意点
- カテゴリ変数の数値化手法① One hot Encoding(ワンホットエンコーディング)
- カテゴリ変数の数値化手法② Label Encoding(ラベルエンコーディング)
- カテゴリ変数の数値化手法③ Count Encoding(カウントエンコーディング)
- カテゴリ変数の数値化手法④ Target Encoding(ターゲットエンコーディング)
- リークの注意
※この講座は所属企業や所属団体とは一切関係ありません
はじめに

今回は「カテゴリ変数の扱い方」として、機械学習モデルを使う上でポイントとなるカテゴリ変数の数値化について焦点を当てた。カテゴリ変数は身長や体重のように数値で表せる(数値に意味のある)変数ではなく、「好きな色」の様に区別するための尺度のことをいう。
したがって、例え数値であっても学校のクラスのように1組、2組、…のように数値自体に意味のないものはカテゴリ変数となる。機械学習を行う上で決定木などはカテゴリ変数をそのまま扱うことができる。しかし、ロジスティック回帰やニューラルネットワークでは、そのまま扱うことは出来ず、数値に変換する必要がある。
また、決定木系の機械学習モデルでも、工夫して数値に変換することで精度向上に寄与することがよくある。
今回は、代表的な数値変換方法として、One hot Encoding、Label Encoding、Count Encoding、Target Encodingについて解説する。また、カテゴリ変数を扱う上での注意点についても解説する。
カテゴリ変数を扱う上での注意点

カテゴリ変数を扱う上で、注意することはたくさんある。その一つとしてカテゴリの「細かさ」について今回は取り上げる。例えば、何かを予測する際に使用するデータとして、所有する車個別の名前があったとした場合に、そのまま説明変数として使用すると、分類が細かすぎて上手く学習ができなかったり、業務で機械学習モデルを何年も運用することを考えると新発売の車個別の名前に対応できなかったりする。
このような時は、例えば排気量をカテゴリとすればカテゴリの細かさも適度になり目的変数との関係が見えやすくなることもある。あくまでケースバイケースなので、データをじっくり眺めながら仮説検証を繰り返し、分析結果に基づいて上手に加工する泥臭い手間が大切になる。
カテゴリ変数の数値化手法① One hot Encoding(ワンホットエンコーディング)

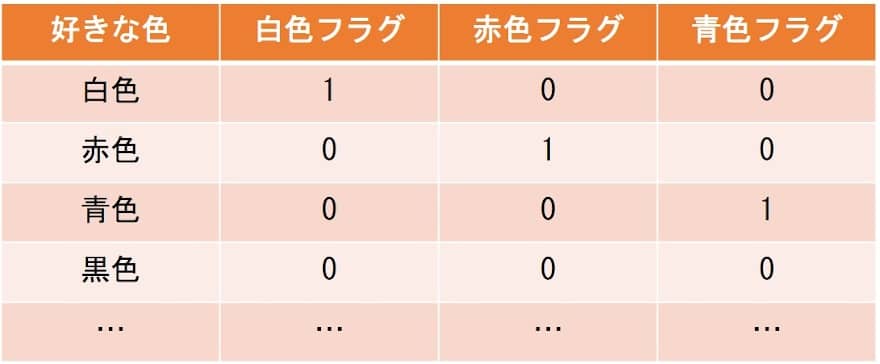
カテゴリ変数を数値化する簡単なやり方として、One hot Encodingと呼ばれる手法がある。ダミー変数化ともいい、単純にそのカテゴリに該当するか否かで0、1のフラグを作成する手法である。例えば、好きな色として挙げられたデータが全部で白色、赤色、青色、黒色だったとする。
このとき、新しい変数として「好きな色が白色フラグ」「好きな色が赤色フラグ」「好きな色が青色フラグ」を作成して、該当すれば1、該当しなければ0を入れる。このとき、好きな色が黒色については「好きな色が白色フラグ」「好きな色が赤色フラグ」「好きな色が青色フラグ」が全て0となることによって表現することができる。この手法では、変数がカテゴリの数から1少ない個数分できるので、横に長い、しかもほとんど0ばかりのデータになる欠点があります。
カテゴリ変数の数値化手法② Label Encoding(ラベルエンコーディング)

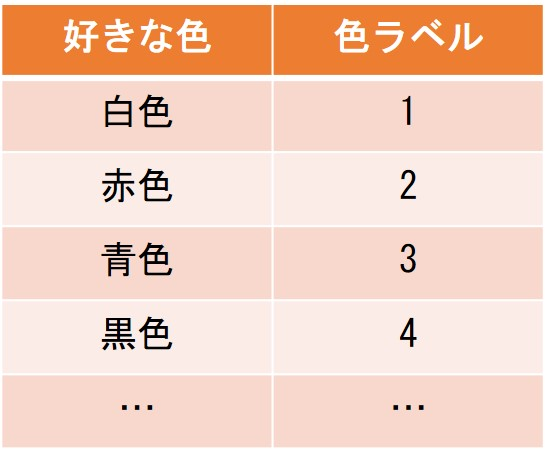
カテゴリ変数を数値化するもう一つの簡単なやり方として、Label Encodingと呼ばれる手法がある。これはOne hot Encodingと違い新しく作成される変数は1つで済む。やり方は単純に各カテゴリに対して数値Labelを割り割り振る。
例えば好きな色の例であれば、白色は1、赤色は2、青色は3、…のようにIDとして数値に変換する。この手法では数値の大小に意味がないので、決定木の分岐やロジスティック回帰や重回帰では良い結果が得られにくい数値変換となることが多い。
カテゴリ変数の数値化手法③ Count Encoding(カウントエンコーディング)

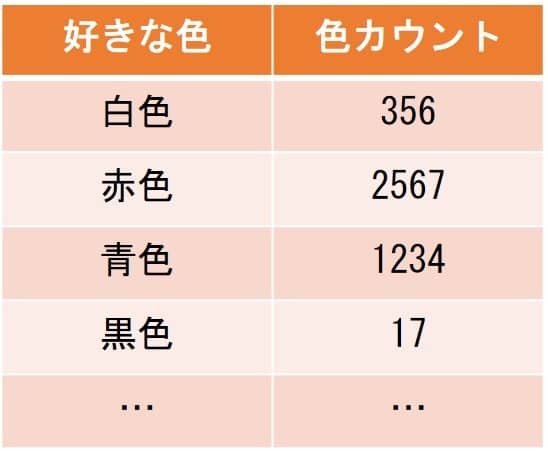
カテゴリ変数を数値化するさらにもう一つの簡単なやり方として、Count Encodingと呼ばれる手法がある。これは、各カテゴリのデータでの登場回数をそのカテゴリの数値として割り振るものである。
例えば好きな色の例であれば、データ全体で白色が好きな件数が356件、赤色が好きな件数が2567件、青色が好きな件数が1234件、黒色が好きな件数が17件だとすると、そのまま白色は356、赤色は2567、青色は1234, 黒色は17と数値に変換する。この手法ではLabel Encodingと違い、数値に意味があり、目的変数との関係が見えやすくなる場合もある。Label Encodingと比較して、決定木の分岐やロジスティック回帰や重回帰で良い結果が得られる可能性も高くなる。
しかし、あくまでデータ上での登場回数なので目的変数との関係が掴みにくい。
カテゴリ変数の数値化手法④ Target Encoding(ターゲットエンコーディング)

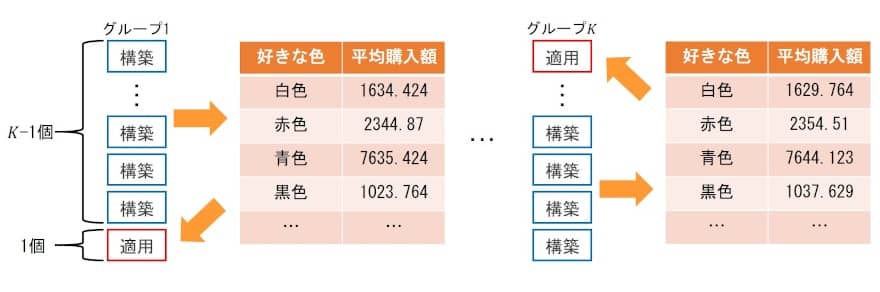
カテゴリ変数を数値化する方法として、Target Encodingと呼ばれる手法がある。これは上記までの数値変換方法と違い、目的変数の情報を上手く使うやり方となる。ただし、目的変数の情報を説明変数に使用するので、後述するリークに注意することが必要となる。Target Encodingはカテゴリごとに目的変数の平均をそのカテゴリの数値として割り振るものである。
例えば、目的変数をある通販サイトの1ヶ月の累計購入金額とすると、好きな色の例(登録ユーザにアンケート等で聞いたという設定)では、白色が好きな人の平均の購入金額が1634.424円、赤色が好きな人の平均の購入金額が2344.87円、青色が好きな人の平均の購入金額が7635.424円、黒色が好きな人の平均の購入金額が1023.764円だったとすると、その数値を各カテゴリに割り振って数値変換をする。
この手法では、これまでと違い数値が高ければ目的変数も高い傾向にあり、数値が低ければ目的変数も低い傾向にあることが分かる。したがって、これまでの手法と比較して、決定木の分岐やロジスティック回帰や重回帰で良い結果が得られやすい。線形回帰系の機械学習モデルで行う変数の線形加工もTarget Encoding後はしなくても済む。
リークの注意

リークとは、本来想定されていない方法で、目的変数あるいはそれに近いものが説明変数に漏れていて、機械学習モデルが学習してしまうことをいう。リークがあると、実際の運用時に想定よりも精度の低い機械学習モデルが作成されてしまう。
Target Encodingでは目的変数の情報を「目的変数の平均」として、説明変数に組み込んでいる。これによってリークを起こしやすく、精度が過剰に高く出やすくなる。これを回避するには第2回に紹介したCross Validation法を応用してリークが起きないようにTarget Encodingする必要がある。

- 寄稿
- Kaggle Master
佐野 遼太郎 氏2015年4月よりコンサルタントとして金融機関を中心とした
データ分析・モデル構築業務に従事。
2018年2月にKaggler枠で株式会社ディー・エヌ・エーに入社、
現在は株式会社Mobility Technologiesに出向中。
また、2016年から社外データ分析講座講師として
300人を超えるデータ分析技術者の人材育成に関わっている。










