

※この講座は所属企業や所属団体とは一切関係ありません
人間がデータを丁寧に確認する

データ分析を始める上で最も大事なことは、「高度な統計手法の理解」でも「高度なプログラミングスキル」でも「高度な機械学習手法の理解」でもなく、「データを穴が開くほど眺める力」である。利用するデータを一つひとつ丁寧に眺める必要がある。「データの仕様書と実際の中身が違っていた」なんてことはよくある。機械学習を用いた予測モデルを作成する場合、その学習データが間違っていたとなると事故の元となる。
また、次回の「機械学習モデルの作り方」でも説明するが、機械学習モデル構築の観点では汎用性のない変数を除いたり、適切な加工をしたりする必要がある。さらには、機械学習モデルの予測結果に対しても、精度の高低だけでなく、どんなデータには精度良く予測していて、どんなデータには精度が悪いのかなどを確かめることが重要にもなってくる。
したがって、データ分析を行う人は泥臭くデータと向き合う力が一番重要になってくる。データをAI(人工知能)に渡したら適当に何か良い予測をしてくれるかと言ったら、そんなことはないということを認識してほしい。人間がきちんとデータを確認する必要がある。
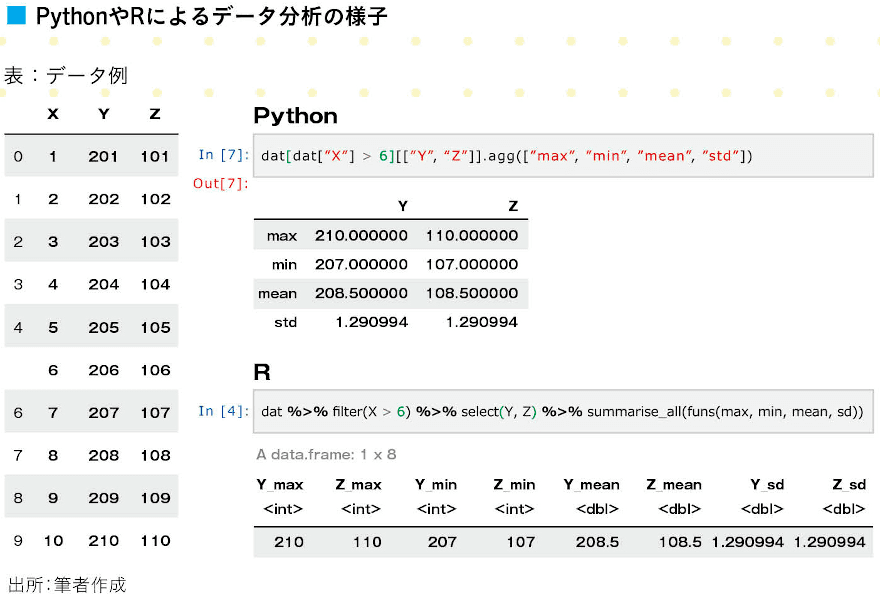
複雑な分析がお手軽にできるPythonやR

プログラミング講座では無いので、ここでは詳細な説明は省くが、「X > 6のデータに制限して、YとZの最大値、最小値、平均値、標準偏差」を出す工程が1行でできる手軽さを確認したい。
下の表を見てほしい。このように、一般的なプログラミング言語であるPythonでもRでも、お手軽に集計できる。このぐらいはExcelでもお手軽にできるかもしれないが、実際はデータを結合したり、大きいデータを扱ったり、複雑な加工をしたり、可視化をしたりと、柔軟にデータをハンドリングする必要がある。
データ分析を本格的にやる場合はPythonやRの使用をおすすめする。もちろんBI(ビジネスインテリジェンス)ツールではできない柔軟な分析が可能だ。プログラミングを覚えるコストはあるが、そのコストはそこまで大きくないし、すでに何かしらのプログラミング言語を扱っている方は簡単に導入できる。
Kaggleで多種多様なデータに触れる

今の世の中は便利なもので、インターネットで検索すればコピーアンドペーストで誰でもAIを作ることができる。PythonやRによる機械学習モデルを作成するサンプルプログラムは多く公開されている。また、高度な機械学習モデルである「勾配ブースティング決定木」や、ディープラーニングも同様にサンプルプログラムが公開されている。
したがって、ITリテラシーがそれなりにあれば、見よう見まねでAIを作成すること自体はできるのである。もちろん、サンプルプログラムを使用しただけでは、本当の意味で精度の良い、目的に適した機械学習モデルができるわけではない。大事なポイントは「利用するデータの選定」、「使用する機械学習モデルの選定」、「特徴量の作成や変数加工」、「目的に合わせた精度評価」が挙げられる。これらの大事なポイントを“手を動かして”学ぶ必要がある。
一番手っ取り早い方法がKaggle(カグル)と呼ばれるデータ分析コンペティションに参加することである。Kaggleとは世界中のトップデータサイエンティスト達が予測精度を競っているプラットフォームである。ここでは、世界のトップデータサイエンティスト達の「データの眺め方」、「機械学習構築方法」、「精度向上テクニック」、「考察の仕方」などがPythonやRなどのコード付きで閲覧できる。
もちろん参考のための閲覧だけでもよいが、それだけだと中々身につかない。“習うより慣れろ”と言うように、実際に開催されているコンペに参加するのが一番効率的だ。最初から予測精度の良いモデル構築はできないし、初学者だととんでもなく悪い順位となるかもしれないが、それはみんなが通る道。大事なことはまずは手を動かすこと、まずはサブミット(予測結果を投稿し順位が分かる)してみてほしい。
Kaggleの良い点として、様々なデータに触れられることが挙げられる。業務だけでは限られたデータにしか触れられないかもしれないが、Kaggleでは多種多様なデータに触ることができる。また、失敗できることも挙げられる。実際の業務で機械学習モデルを使用した場合に失敗したら大変なことである。しかし、Kaggleで失敗してもコンペの順位が低いだけで損害は無い。Kaggleで試行と失敗を繰り返すことで自然とデータ分析の経験を積むことができるわけである。
理論よりも実際のデータから学ぶ

2020年現在、作成した機械学習モデルを適切に評価するのは、まだ人間である。使用したデータのドメイン知識などを考慮し、目的に合わせて評価する必要があるが、この作業はまだまだ人間にしかできないし、5年後も変わっていないと考えられる。「説明変数は妥当なものか」、「簡単な機械学習モデルと比較して異常に精度が高くないか」、「過去データと未来データはどれくらい同質か」などをきちんと考慮する必要がある。
機械学習やAIという言葉はかっこよく見えたり、スマートに見えるかもしれないが、大事なことは上述のように泥臭い作業となる。これからデータ分析を始める方は、手を動かして泥臭い作業を行い、機械学習を体得する気構えで始めていただけたら、より深いデータ分析技術、機械学習構築技術が身につくと私は考える。
座学で機械学習の理論や、PythonやRの問題集をやることもよいが、まずは実際のデータに触れて、データを眺めようとして、必要な知識やプログラミング技術をかき集めるようにして鍛えていくことが、ひとつの良いデータ分析の始め方かと考えている。
とはいえ、やはり理論も大事である。ただし、関数解析など高度な数学を含めて理解する必要はない。モデルが何をやっているのかを把握できる程度には、モデルの中身(理論)を理解する必要はある。
社会人だと中々時間を取ることができないので、まずは手を動かすことをおすすめしたが、ある程度手を動かせるようになったら、「使用しているモデルについて何を最適化しているのか」、「どのように最適化しているのか」、「各ハイパーパラメータはどのような意味を持って、どのような影響を与えるのか」を把握しておくと良い。より高精度なモデル作成にも結び付くし、実際の運用時の事故を防ぐこともできる。
データ分析初心者は必ずしも数学に強い必要はない

データ分析に適性のある人材は決して数学に強い人間だけではない。実際に学生時代は法学や経済学を専攻していた人で、優秀なデータ分析人材となっている人を知っている。
大事なことは「穴が開くほどデータを見る」「必要な知識をかき集める」ことなどが挙げられる。泥臭くデータと向き合うことのできる人材であれば、決して現時点で数学に強くプログラミングに強い必要も無い。
下記が私の考えるデータ分析に向く人材の5つの要素である。参考にして頂ければ幸いだ。
①プログラムと数字にアレルギーがなく、嘘を付かない
②質問に来る前にデータを確認することができる
③質問に来る前にプログラムのエラー文を検索している
④泥臭い作業ができる(例えば50変数ぐらいなら分布を一つひとつ確認する)
⑤思い付いたら、まずは試してみる

- 寄稿
-
Kaggle Master
佐野 遼太郎 氏
Kaggle Masterの称号を持つ。2015年4月よりコンサルタントとして金融機関を中心としたデータ分析・モデル構築業務に従事。2018年2月にKaggler枠でディー・エヌ・エーに入社、現在はMobility Technologiesに出向中。また、2016年から社外データ分析講座講師として300人を超えるデータ分析技術者の人材育成に関わっている










