

背景
第2回「【連載】XVAの基礎と実践② XVAデスクの設置とフロント実務」の中で、CVA計測時の計算コストの課題を説明した。
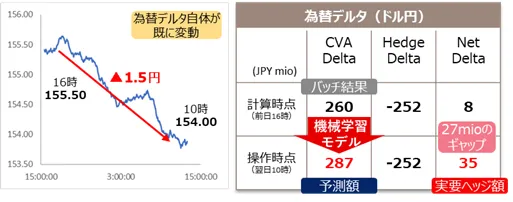
再掲すると、ポートフォリオ全体に対するCVA及びそのセンシティビティを計算するには膨大な計算時間が必要であり、トレーダーがリアルタイムでリスク量を把握することが困難になるというものであった。タイムスケジュールを例示すると、東京16時時点のマーケットデータを元に夜間バッチで計算する場合である。
リアルタイムでのマーケットの下での厳密な計算は現実的には実施できないため、トレーダーは実質的に数時間以上前で、ロンドンやニューヨーク時間での変動を勘案していないマーケットデータで計算されたポジションを基準に操作した場合、ミスヘッジによる損失やヘッジコストの増加を招いてしまう。特にこのような状況が、流動性が非常に高く変動が大きい為替レートのリスク(為替デルタ)において生じやすい。なお、CVAトレーダーはこの特性を理解しているため算出値に過去の経験等を踏まえてポジション量を推計しているのが現実である。
また、CVAではその計算式の特性として、ネガティブガンマと呼ばれる(為替のみが変動した場合、デルタ変動が為替変動と逆符号になる)リスクを持ち、デルタリスクをゼロ(デルタニュートラル)にしていても為替変動に対して損失が発生するような構造になっている。それゆえ、為替デルタのコントロール、そのためのリアルタイムでの為替デルタ量の把握が重要な課題となる。
リアルタイムでの計算を実現する手段として第2回で紹介したような分散処理・自動微分の活用等による計算高速化を取りうるが、この方法は開発に膨大なコストがかかり現実的には難しい可能性もある。
そのような場合にこの課題を解決する為、厳密な再計算にこだわらず近似値を推計する、というように発想を切り替えてみる。推計を行う、ということは機械学習が得意とするものであり、ここに機械学習技術活用の可能性が生まれる。為替デルタ(ドル円)の場合のCVAデルタの誤差が±3百万円である確率が80%程度と実用上十分な精度を持ちつつ、数時間かかる厳密計算を数分程度で近似値推計する機械学習モデルを構築、実用化に成功した。
機械学習としての問題設定
機械学習の観点から見ると、CVAやそのセンシティビティの計算は
・「入力(マーケットやポートフォリオのデータ)」から
・「出力(時価やセンシティビティ)」を与える
という関数としてシステム上実装されているが、その関係性は非常に複雑であり、単純な数式では表現できないブラックボックスになっている、と捉えることができる。
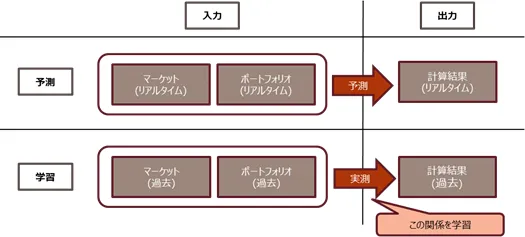
本件課題は、入力から厳密に出力を与えるのに多大な時間が必要となる、というところにある。この入力から出力への関係性を、過去のシステム計算結果を元に機械学習モデルに学習させ予測する、という問題設定(回帰問題)を考えるのである。予測というとマーケットの予測を思い浮かべるかもしれないが、本件はそれとは異なり、システム上の計算結果を予測するというアプローチを取る。
より具体的には、前日夜の夜間バッチ計算で用いたマーケット及びポートフォリオデータ、およびリアルタイムでの同データを入力としてリアルタイムでの計算結果を予測する、というように問題を設計する。マーケット・ポートフォリオデータを入力として計算結果を出力する、というこの関係性を過去データから学習し、得られた関係性(回帰関数)を用いてリアルタイムでのデータから計算結果を予測するのである。
このような形で、本件課題をこのような機械学習の問題を精度よく予測するモデルを作る、という課題に帰着できたが、これを実現するためには様々な工夫が必要となる。以下3, 4節でその具体例を紹介する。
利用データの設計
これを実現する機械学習モデルを考えるに当たり、まずはデータの観点から①ポートフォリオ状況を表現するデータとして何を利用するか、②予測対象を具体的に何にするか、を定める必要がある。
ポートフォリオデータの定義
CVAにおいては、ポートフォリオの構成要素は明細キャッシュフロー、ISDAやCSA契約の内容であり、これらのデータはシステム計算で用いるために集約されているであろう。機械学習モデルでこれらのデータを利用するには整えられたデータ、例えばテーブルデータに整理する必要があるが、このようなキャッシュフロー・契約情報は1基準日1行としてテーブルデータ化するのが非常に困難である。そのためポートフォリオの情報を示す代替手段が必要となる。この手段として、過去(例えば前日)基準の時価やセンシティビティの計算結果を用いることが考えられる。
実際、例えばUSD/JPY通貨スワップを取引している顧客に対するCVAにおいては、USD/JPY為替スポットやUSD, JPY金利のリスクが発生するが、EUR/JPY為替スポットやEUR金利のリスクを直接に発生しない(時価やエクスポージャがこれらのマーケットに直接依存する取引を持たないため)。従って、どのリスクにどの程度の規模のセンシティビティが発生しているか、という情報は当該顧客とのポートフォリオに対する情報をある程度十分に持っていると仮定してもよいのである。
なお、この場合リアルタイムのポートフォリオデータはリアルタイムでの計算結果になってしまい、予測対象を使って予測しようとするというようなトートロジーが生じるように見えるが、ポートフォリオデータはマーケットデータのように日々大きく変動するものではないと仮定すれば「リアルタイムのポートフォリオデータ=前日のポートフォリオデータ=前日の計算結果」としてしまっても十分であろう。ポートフォリオの大きな変動、例えば規模の大きい新規明細によるポジションについては件数が少ないと考えられる。これに対しては計算量が少ないと想定できるため、機械学習モデルを利用せずにリアルタイムポジションをシステム計算して管理することも可能であろう。
予測対象の設定
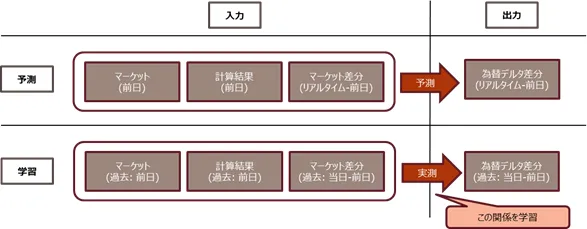
為替デルタ計算結果を予測対象とする、といっても水準そのものを予測するか、あるいは前日からの差分を予測するかという選択肢がある。本件では後者を利用するのが望ましいだろう。実際、本件は時系列予測を行う問題ではないものの、データ自体は時系列で与えられており、各データはその前日の計算結果に強く依存する(ポートフォリオ構成やマーケットデータ水準は前日の内容から全く別物にはならない!)。この場合、予測対象を為替デルタ水準とすると、それを予測するための特徴量、例えば前日の為替デルタ水準の強すぎる相関(自己相関)を学習してしまい、他の要素をうまく学習できなくなる。
これに合わせて、特徴量として前日水準及びマーケットについては前日からの差分も利用する。こうすることで、モデルの解釈として「前日水準を発射台としてマーケット変動から為替デルタの変動を予測する」という、より分かりやすい解釈を与えることもできる。
ただし、差分を予測する場合、事後処理としてリアルタイムのポジションを「前日バッチ結果+予測結果」として計算する後処理を行うひと手間が必要になる点は注意しよう。
上記アイデアの下、最終的には機械学習モデルとしての構成は図3のようになる。
精度向上に向けたアイデア
上記データ設計に合わせたデータが取得・整理できればいよいよ機械学習モデルの作成を実行できるが、典型的なライブラリ・アルゴリズムにデータをそのままを投入してモデルを作成しても十分に精度が上がらないであろう。精度を向上させるためにはその課題に即した工夫が必要になるが、本課題では以下のようなアイデアが考えられる。
データの分割
本件は膨大な計算コストが課題であるため、機械学習用にデータを大量に用意することは難しい。従って利用できるデータは日次で算出されているシステム入力算と出力値になる。全ポートフォリオベースのデータを利用する場合、例えば3年分の過去データがあればデータ数は700データ程度になる。この数は特徴量種類、特に入力マーケットが1,000種類程度(パラレルにしても数十程度)、また3~4年の中でもマーケットは大きく動き様々なケースがありうるという状況に対してこのデータ数は少ない。かつ、予測したいのはリアルタイムマーケットの下での計算結果でるため、直近の環境をうまく学習させることが望ましい。
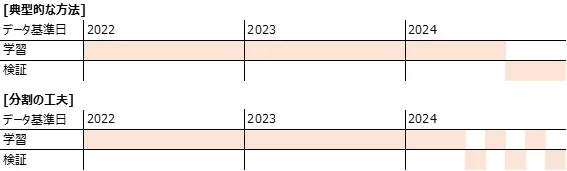
少ないデータを活用して直近環境を学習させるためのアイデアとして、定期的な再学習を前提として足元のマーケット環境・ポートフォリオ状況を学習に反映できるよう学習・検証データを分割するという方法が考えられる。様々な期間のマーケット環境を学習できるよう、例えば図4のように足元1年分の中で学習・検証データを交互にとるというようなこともできる。
なお、本件課題を時系列予測として捉えてしまうと、このような分割は望ましくないものに見えるだろう。実際、時系列予測においてはデータの時系列が重要であるため学習・検証用のデータ期間が連続的になるように定めなければならない。かつ、各時点のデータはそれより過去のデータを反映していると考えられるため、直近のデータを(学習データから見て未知のものとなるように)検証データとして利用、それ以前のデータを学習データに用いる必要がある。
一方、本件はあくまで入力から出力への関数(システム計算)を近似値推計する、という問題であるので、基準日はデータを区別するための単なるラベルとして見ても時系列予測と捉えたときのような支障は生じないだろう。
細かな点では、分割したデータ間での重複がなければ(例えば、検証データ中での前日等過去基準日特徴量が別特徴量として学習データに利用されないように期間を定めれば)このようなリスクは十分に小さい。
事前知識の取り込み
トレーダーは為替デルタの変動を考える上で為替ガンマを利用することが多いが、こういった業務知識を事前知識としてモデルに組み込むことができる。本件であれば、事前に推計した為替ガンマを用いてモデル予測対象を「デルタ変動 – 為替ガンマ×為替変動」として為替ガンマの要因を除いた残差とモデルに学習させる、といったことも可能である。この場合、最終的な為替デルタ予測値は「前日為替デルタ+為替ガンマ×為替変動+機械学習モデルでの残差予測値」という形になる。
このような事前知識もモデルが学習できることを望みたいが、モデルがデータだけでゼロから学習できるかは保証できない。あらかじめ人間がモデル構成の中で織り込んでおくことでその可能性を高める、あるいはそれ以外の変動要因に重点を置いて学習させる、といったことが実現できる。
これ以外にも、①のようなデータの扱いの発展として仮にカウンターパーティごとの計算結果が利用できるのであれば個社毎や部分ポートフォリオのデータも利用データに加えることでデータ拡張(augmentation)し、より広範なポートフォリオに対する学習を行い精度の改善が実現できる可能性もある。②の発展であれば、為替ガンマではなく、ある断面でシミュレーションした為替に対する為替デルタのシミュレーション結果を利用することで精度が改善する可能性もあるだろう。このように様々な改善アイデアが得られるであろうが、モデル学習時間の増大な事前シミュレーション計算コスト等、モデルの運用負荷が高まる。できあがりの精度水準と運用負荷のバランスを考えてモデルの高度化を考えることが重要である。
まとめ
機械学習の活用はXVA領域に限らず非常にチャレンジングなテーマであるが、XVAならではの課題に活用できるチャンスもある。本稿ではその具体例及び活用に向けた様々なアイデアを提示したが、機械学習活用で重要なのは、まずは利用できるデータで実現できる範囲を見定めつつも、実用化に向け試行錯誤を繰り返しながら使っていくというパイオニア精神であると筆者は考える。
本稿がその実現並びにXVAコントロール高度化に向けての一助となれば幸いである。

- 寄稿
-
株式会社三菱UFJ銀行
金融市場部 CPM室 ポートフォリオマネジメントGr
榎本 拓実 氏XVAデスクにてデスククオンツ業務に従事。XVA計測モデル・システム開発、XVA業務への先進技術導入を推進。(京都大学大学院理学研究科修了)
▼XVAの連載はこちら▼











