

なぜ「リスクをとる」必要があるのか
「虎穴に入らずんば虎子を得ず」
誰もが知っているこのことわざに、リスクというものの本質が端的にあらわれている。虎が住む穴に入れば、虎に食べられてしまう可能性がある一方で、無事に生きて戻れば、虎の子という大きな宝物を手にすることができる。何かを失う可能性と引き換えに何かを得ようとする行動、これが「リスクをとる」ということである。
お金を貸すのもまったく同じことである。誰かにお金を貸せば、返ってこない可能性がある一方で、無事であれば利息の分だけ増えて返ってくる。貸したお金が返ってこない可能性と引き換えに利息を得ようとする行動、言い換えると、お金が返ってくることを信じて裏切られるリスクをとること、これが「信用リスクをとる」という意味である。銀行が手がける貸出業務は、すべて、信用リスクの対価として利息でもうけるビジネスと理解できる。
リスクという言葉には何やら危険な雰囲気も漂うが、信用リスクの場合、小さければ小さいほどよいというものではない。信用リスクがゼロなら、貸したお金が必ず返ってくることを意味する。虎の住まない穴に虎の子がいないのと同じように、返ってくることが確実な相手にお金を貸しても、大きくお金が増えることはない。逆に、返ってくることが非常に疑わしい相手に貸す場合には、大きな見返りを求めなければ割に合わない。
銀行が貸出業務で収益を上げるためには、ハイリスク・ハイリターン、ローリスク・ローリターンというリスクとリターンの性格を十分に理解したうえで、取るべき信用リスクの大きさをほどよいレベルに調整する技術が必要になる。これが「信用リスク管理」のノウハウである。
信用リスクとは

信用リスクとは
先ほど述べたように、信用リスクとは「貸したお金が返ってこない可能性」のことである。たとえば、「トヨタ自動車」のような誰もが知る大企業と、誰も知らない名もなき零細企業とでは、どちらがより確実にお金を返してくれそうか、つまり信用できるかというと、一般的には大企業のほうが信用されやすい。この場合、大企業は信用リスクが低く、零細企業は信用リスクが高い、ということになる。
では、信用リスクの高い零細企業には誰もお金を貸せないのかというと、決してそうではない。高い信用リスクに見合うだけの高い金利が得られるのであれば、それをチャンスと見る貸し手があっても不思議ではない。また、信用リスクは貸し手がそれぞれの「目利き力」で判断するものである。ある銀行にとっては信用リスクが高く見えても、ほかの銀行から見れば大丈夫、などという場面もあるかもしれない。
信用リスクをとる・とらないの判断
貸す・貸さない、信用リスクをとる・とらないの判断は、貸したお金が返ってこない可能性と、返ってくる場合に得られる金利、つまり、リスクとリターンとの比較で考えるべきものである。これを簡単な数式であらわすと、次のようになる。

ということで、貸す・貸さないの判断のためには、貸したお金が返ってこないときの損失額を、あらかじめ正確に計算する必要がある。そして、この損失額を得られる利息が上回る見通しであれば、貸しても損にはならないと判断できる。
このとき「利息は数パーセントしかとれないのに、貸したお金が戻ってこないときには全額が損になるのだから、これではどうやっても貸せるはずがない」と考えた方は、同時に10人にお金を貸す場面を思い浮かべていただきたい。
10人に貸せば、全員が返せないのか、一人だけが返せないのか、その見通しの違いによって上の式の結果が変わることをイメージできるのではなかろうか。以降の説明では基本的に、1件ごとではなく、銀行のように、多数の貸出先を相手にする場面での信用リスク管理を想定している。
信用リスクと予想損失率(EL)

予想損失額と予想損失率
貸したお金が返ってこないときの損失をあらかじめ見積もった金額のことを「予想損失額」、略してEL(expected loss)という。
そして、貸出金額全体に対する予想損失額の割合のことを「予想損失率」という。先ほどの式を貸出金額で割り算すると、「予想損失率」「貸出利率」にそれぞれ書き換えることができる。したがって、リスクとリターンの比較とはつまり、予想損失率と貸出利率をくらべるのと同じことである。

予想損失率の計算方法
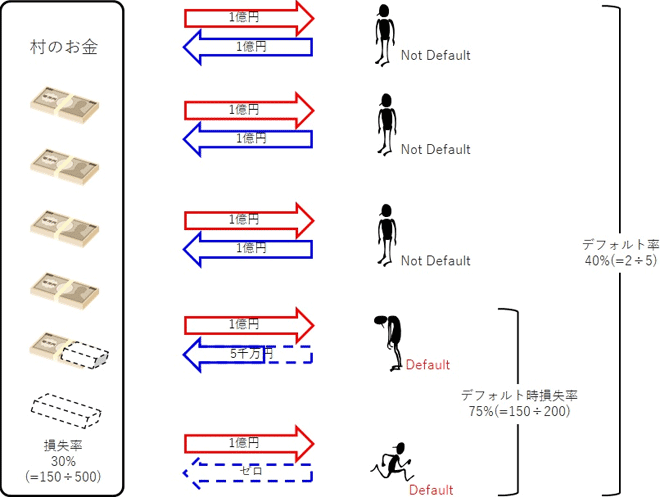
貸出利率は最初から約定で決まっているものとして、予想損失率はどのように計算できるか。ここでは、ある老人が、村の若者5人に100万円ずつお金を貸したケースをもとに考えてみることにしよう。
若者のうち3人は1年後に返すことができたが、残る2人は返すことができず、うち一人は謝りにやってきて半額を返した。そしてもう一人は全額を持ち逃げしてしまった。このとき老人はトータルで、150万円(=50万円+100万円)を損したことになる。毎年多額の損失が出るのではたまらないので、老人は、来年からは損にならないように利息をとろうと考える。このとき、来年の若者も今年の若者と同じような行動をとると仮定すると、予想損失率は次のように計算できる。

したがって、来年の若者からは30%の金利をとれば、老人は損を出さずに済むと考えられる。このように信用リスクの大きさは、予想損失率の大きさによって評価することができる。
デフォルト率(PD)とデフォルト時損失率(LGD)

デフォルト率
それにしても30%の金利では、若者もさすがに借りるのをためらうかもしれない。そこで老人は、少しでも金利を下げるために、予想損失率を下げることを考える。老人は、予想損失率の裏側に二つ数字があることに注目した。一つはそもそも返せるのか返せないのか、もう一つは返せなくなった人からどの程度回収できるのか、である。
返せるのか返せないのかに関係するのが、全額を返すことができなかった、つまり1円でも損失を出した人の割合であり、この場合には40%(=2人÷5人)と計算できる。この「期日までに全額を返す」という当初の約束を守れなかったケースを「債務不履行」あるいは「デフォルト」と呼ぶ。そして貸出先全体のうち、デフォルトに至った人の割合を「デフォルト率」という。
また、この予想値のことを特に「予想デフォルト率」、略してPD(probability of default)という。たとえば老人は、来年はあらかじめ面接を行って、まじめと判断した若者にだけお金を貸すことで、予想デフォルト率を下げることができるのではないかと考えるのである。
デフォルト時損失率
次に、返せなくなった人からどの程度回収できるのかに関係するのが、実際に返せなくなった人それぞれにおける損失率である。この例で対象は二名あり、謝りに来たほうは50%(=50万円÷100万円)、持ち逃げしたほうは100%(=100万円÷100万円)である。このように、デフォルトした時の貸出金額に対して、実際に損失に至った金額の割合のことを「デフォルト時損失率」、略してLGD(loss given default)という。
なお、デフォルトした時の貸出金額のうち実際に回収できた金額の割合を「回収率」とすると、LGDは 1-回収率 で計算できる。老人は来年お金を貸す時には、1年後に100万円全額を返してもらうのではなく、3か月ごとに25万円ずつ返してもらう仕組みに変えることで、LGDを下げることができるのではないかと考えるのである。
予想損失率の計算式
このように、信用リスクを評価するための「予想損失率」は、「予想デフォルト率」と「予想デフォルト時損失率」とに分けて考えることができる。実際には、次のような計算式が成り立つ。

適切に信用リスクを管理するためには、一つ一つの貸出の、予想デフォルト率(PD)と予想デフォルト時損失率(LGD)を、それぞれ正しく推計することが肝要である。
債務者格付制度

債務者格付制度
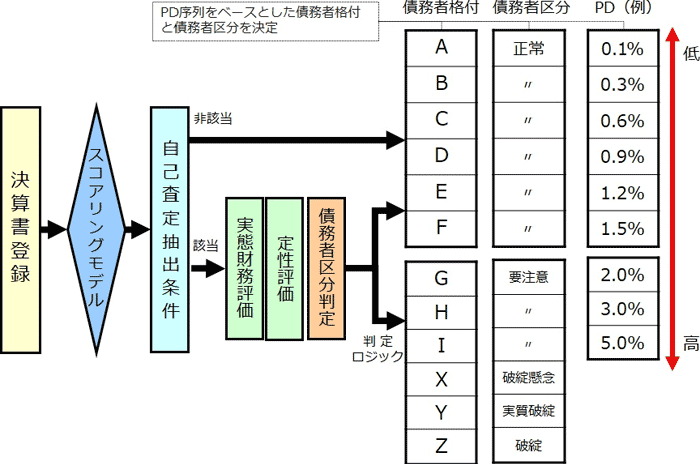
さて、現代の銀行では、貸出先ごとの予想デフォルト率を計算するのに「債務者格付制度」を採用していることが多い。この仕組みを簡単に覗いてみよう。
今あなたは、ある支店で100社の貸出先を担当する銀行員だとしよう。100社それぞれについて、来年1年間のデフォルト率を予想しようと思ったら、どのような手段が考えられるだろうか。
やはり最初に考えられるのは、先ほどの老人と同様に過去の実績に頼る方法であろう。例えば、昨年は貸出先100社のうち3社、つまり3%の割合でデフォルトが発生したのであれば、来年も同じようにデフォルトが発生すると考え、予想デフォルト率を3%とおくのである。
ただしこのやり方だと、すべての貸出先に一律に同じ予想デフォルト率を割り当てることになる。実際には、100社の中には元気な会社もあれば、潰れそうな会社もある。それらの予想デフォルト率を十把一絡げに3%とするのでは、貸出先それぞれのお金を返す能力、すなわち「信用力」と合っていない可能性がある。
そこで考えられるのが、貸出先をいくつかのグループに分けて、それぞれのグループごとに予想デフォルト率を計算する方法である。
できればここで使うグループは、「信用力」に応じたものになっていることが望ましいので、まずは担当者としての経験と勘を生かして、貸出先100社を「優良先」「通常先」「危険先」の3つに区分するのである。100社それぞれの予想デフォルト率を個別に計算するとなると途方に暮れてしまうようなケースでも、100社それぞれについて「優良先=何があっても大丈夫」「危険先=何があってもおかしくない」「通常先=それ以外」という色分けをするぐらいであれば、決して難しい話ではなかろう。
グループ分けが済んだら、あとはそれぞれのグループごとに昨年のデフォルト率を計算すれば、それを今年の予想デフォルト率として使うことができる。
債務者格付制度のもっとも原始的な形を例示したが、債務者格付制度とは、何らかの形で貸出先を信用力の大きさでグループ分けして、それぞれのグループごとに予想デフォルト率を計算して使用する仕組みのことをいう。
スコアリングモデルと債務者格付

スコアリングモデル
「優良先」「通常先」「危険先」の3つに貸出先を区分する際の基準になるのが、先ほどの例では、担当者が考える貸出先の「信用力」であった。一つの支店だけで債務者格付の仕組みを取り入れるのであれば、これでよいのかもしれないが、たとえば銀行全体で導入する場合や、10年、20年と長い間にわたって制度を運用する場合、3つの区分ではなくより多くの区分に貸出先を分ける必要がある場合などは、とても対応しきれないことが容易に想像できよう。
そこで、貸出先の信用力を、より客観的に、効率的に、そして正確に評価する方法として登場したのが「スコアリングモデル」である。スコアリングモデルは、過去の貸出先のデータをもとに、貸出先がデフォルトする確率を統計的に推定する計算式のことである。
現在、多くの銀行が使用する債務者格付のためのスコアリングモデルであれば、貸出先の企業の決算書の情報を入力すると、その貸出先の向こう1年間の予想デフォルト率が瞬時に計算される仕組みになっている。これであれば、担当者の頭の中にのみ存在するようなノウハウに依存することなく、客観的な評価を下すことができるうえに、計算式なのでシステム化も容易である。
また、出てくる結果は予想デフォルト率という数値データなので、3区分だろうが10区分だろうが、貸出先の区分も思いのままである。日本の銀行では特に2000年代に入ってから、債務者格付の仕組みに、統計的手法から生まれたスコアリングモデルを活用する動きが広がっており、いまでは信用リスクを管理する際の中心的なツールとして位置付けられている。特に、大量の貸出先データをもとに統計的手法を通じてスコアリングモデルを作り上げる技術は、昨今話題の「機械学習」の一分野に数え上げられる。そのようなスコアリングモデルが、銀行の信用リスク管理の世界では、20年前から人間に代わってリスクを評価しているのである。これをAI(人工知能)と呼ばずして何と呼ぼうか?
スコアリングモデルの落とし穴
万能に見えるスコアリングモデルだが、絶対に忘れてはいけない重大な特徴がある。それは、スコアリングモデルの出す結果はすべて、モデルを作るときに使用した「過去のデータ」に基づくものであるということだ。そこには、過去にデフォルトしやすかった貸出先の決算書の特徴は、将来にわたって変わることがない、という暗黙の前提が存在している。
実際には、2008年から2009年ごろのリーマンショックの時期など、スコアリングモデルの評価が高いにもかかわらずデフォルトする貸出先が少なからず見られた。これは、そのようなスコアリングモデルの暗黙の前提とは裏腹に、リーマンショック以前と当時とで、デフォルトしやすい貸出先の特徴が変化していたことを裏付ける結果と言える。
過去のデータにもとづくスコアリングモデルを信用リスク管理に活用する場合には、常に、最新のデータと過去のデータとの間で特徴に違いがないのか、「トラッキング」「バックテスト」と呼ばれる検証を繰り返すことが欠かせない。
▼筆者:尾藤剛氏の関連著書
ゼロからはじめる信用リスク管理![]()

- 寄稿
-
日本リスク・データ・バンク株式会社尾藤 剛 氏
取締役 常務執行役員







